mirror of
https://github.com/oobabooga/text-generation-webui.git
synced 2024-09-20 10:35:10 +02:00
SD Api Pics extension, v.1.1 (#596)
This commit is contained in:
parent
5543a5089d
commit
ffd102e5c0
6 changed files with 282 additions and 102 deletions
78
extensions/sd_api_pictures/README.MD
Normal file
78
extensions/sd_api_pictures/README.MD
Normal file
|
|
@ -0,0 +1,78 @@
|
|||
## Description:
|
||||
TL;DR: Lets the bot answer you with a picture!
|
||||
|
||||
Stable Diffusion API pictures for TextGen, v.1.1.0
|
||||
An extension to [oobabooga's textgen-webui](https://github.com/oobabooga/text-generation-webui) allowing you to receive pics generated by [Automatic1111's SD-WebUI API](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
|
||||
|
||||
<details>
|
||||
<summary>Interface overview</summary>
|
||||
|
||||
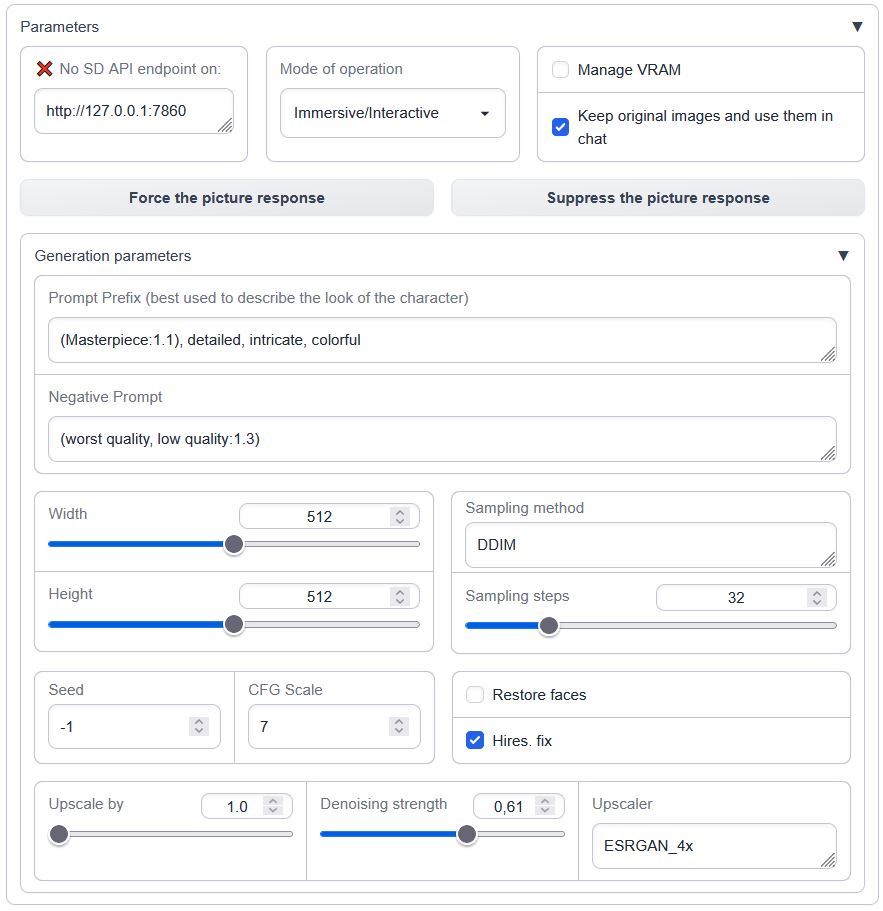
|
||||
|
||||
</details>
|
||||
|
||||
Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures` (it's not really required, but completes the picture, *pun intended*).
|
||||
|
||||
The image generation is triggered either:
|
||||
- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
|
||||
- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
|
||||
- always on in Picturebook/Adventure mode (if not currently suppressed by 'Suppress the picture response')
|
||||
|
||||
## Prerequisites
|
||||
|
||||
One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
|
||||
To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
|
||||
|
||||
## Features:
|
||||
- API detection (press enter in the API box)
|
||||
- VRAM management (model shuffling)
|
||||
- Three different operation modes (manual, interactive, always-on)
|
||||
- persistent settings via settings.json
|
||||
|
||||
The model input is modified only in the interactive mode; other two are unaffected. The output pic description is presented differently for Picture-book / Adventure mode.
|
||||
|
||||
Connection check (insert the Auto1111's address and press Enter):
|
||||
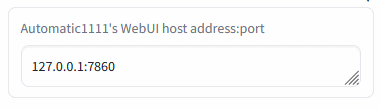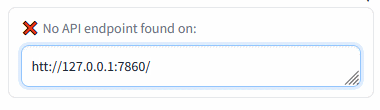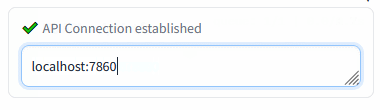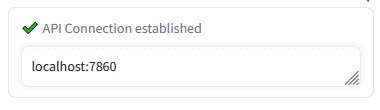
|
||||
|
||||
### Persistents settings
|
||||
|
||||
Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
|
||||
present in script.py, ex:
|
||||
|
||||
```json
|
||||
{
|
||||
"sd_api_pictures-manage_VRAM": 1,
|
||||
"sd_api_pictures-save_img": 1,
|
||||
"sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
|
||||
"sd_api_pictures-sampler_name": "DPM++ 2M Karras"
|
||||
}
|
||||
```
|
||||
|
||||
will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
|
||||
|
||||
---
|
||||
|
||||
## Demonstrations:
|
||||
|
||||
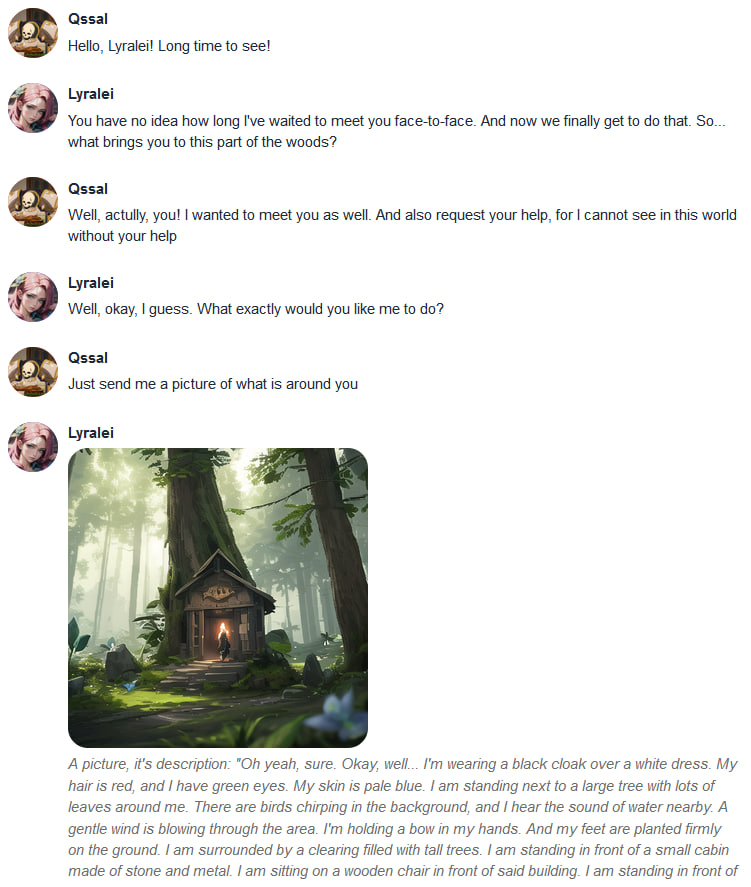
Those are examples of the version 1.0.0, but the core functionality is still the same
|
||||
|
||||
<details>
|
||||
<summary>Conversation 1</summary>
|
||||
|
||||
|
||||
|
||||
|
||||
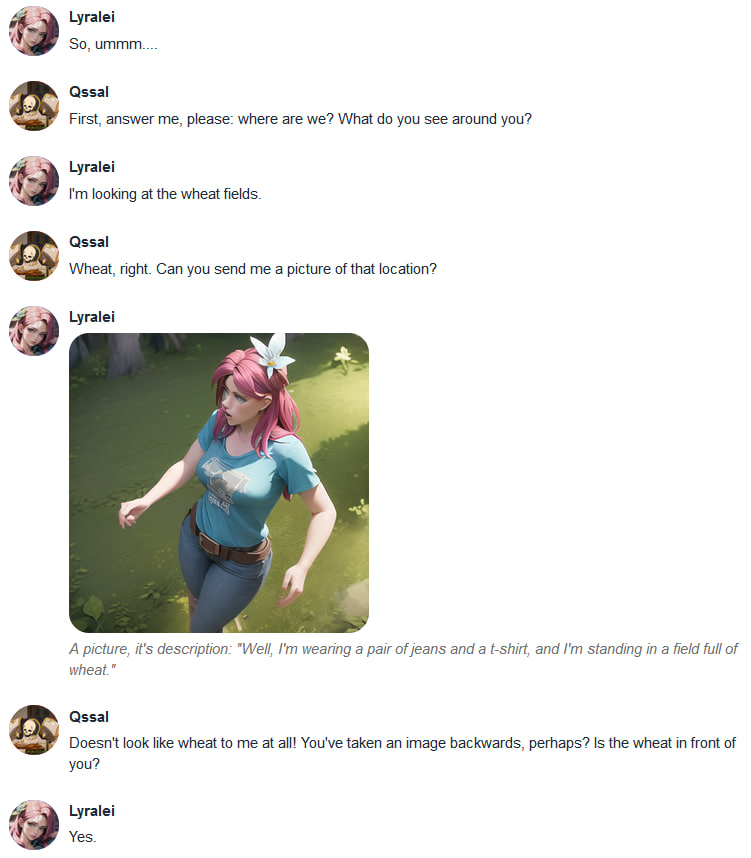
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details>
|
||||
<summary>Conversation 2</summary>
|
||||
|
||||
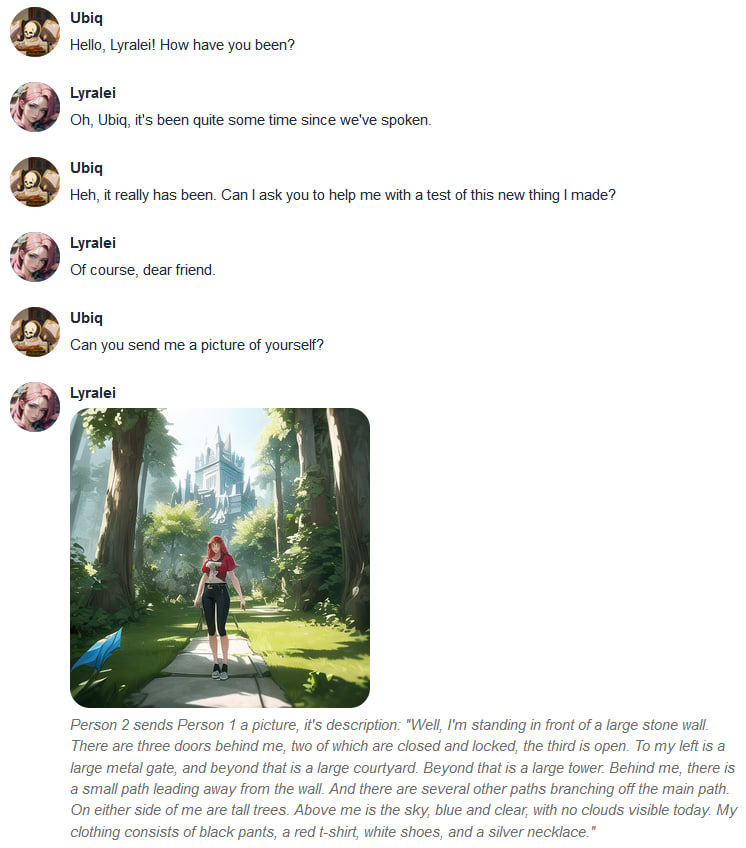
|
||||
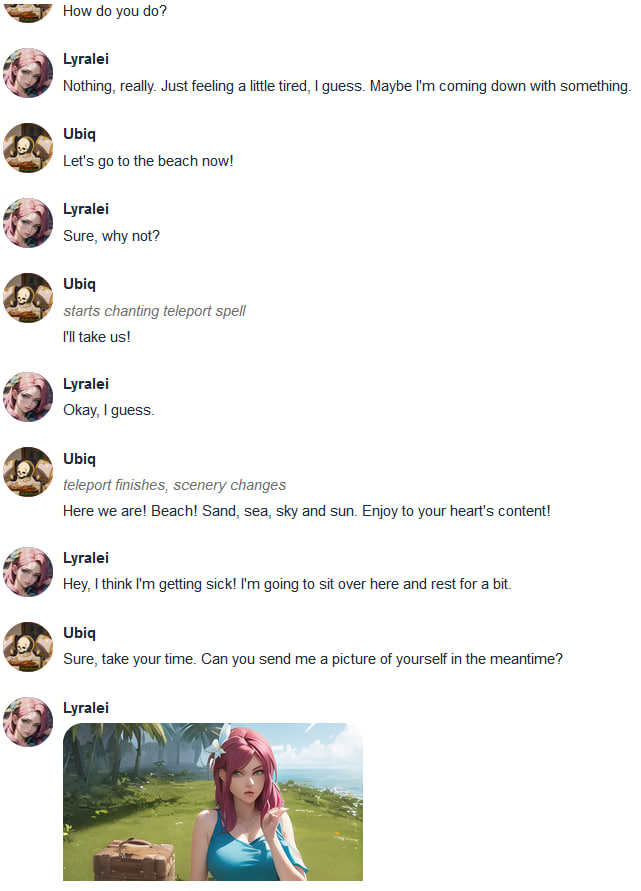
|
||||
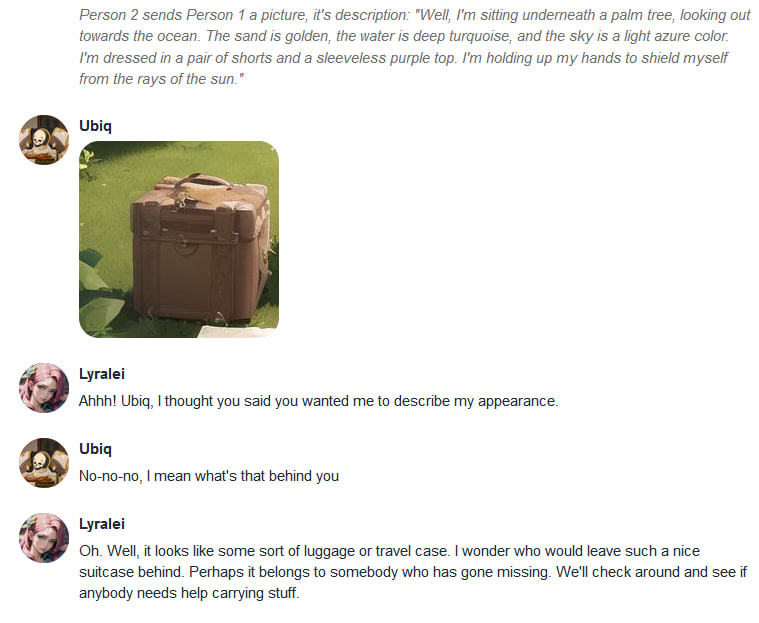
|
||||
|
||||
</details>
|
||||
|
||||
|
|
@ -1,34 +1,78 @@
|
|||
import base64
|
||||
import io
|
||||
import re
|
||||
import time
|
||||
from datetime import date
|
||||
from pathlib import Path
|
||||
|
||||
import gradio as gr
|
||||
import modules.shared as shared
|
||||
import requests
|
||||
import torch
|
||||
from modules.models import reload_model, unload_model
|
||||
from PIL import Image
|
||||
|
||||
from modules import chat, shared
|
||||
|
||||
torch._C._jit_set_profiling_mode(False)
|
||||
|
||||
# parameters which can be customized in settings.json of webui
|
||||
params = {
|
||||
'enable_SD_api': False,
|
||||
'address': 'http://127.0.0.1:7860',
|
||||
'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
|
||||
'manage_VRAM': False,
|
||||
'save_img': False,
|
||||
'SD_model': 'NeverEndingDream', # not really used right now
|
||||
'prompt_prefix': '(Masterpiece:1.1), (solo:1.3), detailed, intricate, colorful',
|
||||
'SD_model': 'NeverEndingDream', # not used right now
|
||||
'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
|
||||
'negative_prompt': '(worst quality, low quality:1.3)',
|
||||
'side_length': 512,
|
||||
'restore_faces': False
|
||||
'width': 512,
|
||||
'height': 512,
|
||||
'restore_faces': False,
|
||||
'seed': -1,
|
||||
'sampler_name': 'DDIM',
|
||||
'steps': 32,
|
||||
'cfg_scale': 7
|
||||
}
|
||||
|
||||
|
||||
def give_VRAM_priority(actor):
|
||||
global shared, params
|
||||
|
||||
if actor == 'SD':
|
||||
unload_model()
|
||||
print("Requesting Auto1111 to re-load last checkpoint used...")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
|
||||
elif actor == 'LLM':
|
||||
print("Requesting Auto1111 to vacate VRAM...")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
reload_model()
|
||||
|
||||
elif actor == 'set':
|
||||
print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
|
||||
elif actor == 'reset':
|
||||
print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
|
||||
response.raise_for_status()
|
||||
|
||||
else:
|
||||
raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
|
||||
|
||||
response.raise_for_status()
|
||||
del response
|
||||
|
||||
|
||||
if params['manage_VRAM']:
|
||||
give_VRAM_priority('set')
|
||||
|
||||
samplers = ['DDIM', 'DPM++ 2M Karras'] # TODO: get the availible samplers with http://{address}}/sdapi/v1/samplers
|
||||
SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
|
||||
|
||||
streaming_state = shared.args.no_stream # remember if chat streaming was enabled
|
||||
picture_response = False # specifies if the next model response should appear as a picture
|
||||
pic_id = 0
|
||||
|
||||
|
||||
def remove_surrounded_chars(string):
|
||||
|
|
@ -36,7 +80,13 @@ def remove_surrounded_chars(string):
|
|||
# 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
|
||||
return re.sub('\*[^\*]*?(\*|$)', '', string)
|
||||
|
||||
# I don't even need input_hijack for this as visible text will be commited to history as the unmodified string
|
||||
|
||||
def triggers_are_in(string):
|
||||
string = remove_surrounded_chars(string)
|
||||
# regex searches for send|main|message|me (at the end of the word) followed by
|
||||
# a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
|
||||
# (?aims) are regex parser flags
|
||||
return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
|
||||
|
||||
|
||||
def input_modifier(string):
|
||||
|
|
@ -44,75 +94,80 @@ def input_modifier(string):
|
|||
This function is applied to your text inputs before
|
||||
they are fed into the model.
|
||||
"""
|
||||
global params, picture_response
|
||||
if not params['enable_SD_api']:
|
||||
|
||||
global params
|
||||
|
||||
if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
|
||||
return string
|
||||
|
||||
commands = ['send', 'mail', 'me']
|
||||
mediums = ['image', 'pic', 'picture', 'photo']
|
||||
subjects = ['yourself', 'own']
|
||||
lowstr = string.lower()
|
||||
|
||||
# TODO: refactor out to separate handler and also replace detection with a regexp
|
||||
if any(command in lowstr for command in commands) and any(case in lowstr for case in mediums): # trigger the generation if a command signature and a medium signature is found
|
||||
picture_response = True
|
||||
shared.args.no_stream = True # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
||||
shared.processing_message = "*Is sending a picture...*"
|
||||
string = "Please provide a detailed description of your surroundings, how you look and the situation you're in and what you are doing right now"
|
||||
if any(target in lowstr for target in subjects): # the focus of the image should be on the sending character
|
||||
string = "Please provide a detailed and vivid description of how you look and what you are wearing"
|
||||
if triggers_are_in(string): # if we're in it, check for trigger words
|
||||
toggle_generation(True)
|
||||
string = string.lower()
|
||||
if "of" in string:
|
||||
subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
|
||||
string = "Please provide a detailed and vivid description of " + subject
|
||||
else:
|
||||
string = "Please provide a detailed description of your appearance, your surroundings and what you are doing right now"
|
||||
|
||||
return string
|
||||
|
||||
# Get and save the Stable Diffusion-generated picture
|
||||
|
||||
|
||||
def get_SD_pictures(description):
|
||||
|
||||
global params, pic_id
|
||||
global params
|
||||
|
||||
if params['manage_VRAM']:
|
||||
give_VRAM_priority('SD')
|
||||
|
||||
payload = {
|
||||
"prompt": params['prompt_prefix'] + description,
|
||||
"seed": -1,
|
||||
"sampler_name": "DPM++ 2M Karras",
|
||||
"steps": 32,
|
||||
"cfg_scale": 7,
|
||||
"width": params['side_length'],
|
||||
"height": params['side_length'],
|
||||
"seed": params['seed'],
|
||||
"sampler_name": params['sampler_name'],
|
||||
"steps": params['steps'],
|
||||
"cfg_scale": params['cfg_scale'],
|
||||
"width": params['width'],
|
||||
"height": params['height'],
|
||||
"restore_faces": params['restore_faces'],
|
||||
"negative_prompt": params['negative_prompt']
|
||||
}
|
||||
|
||||
print(f'Prompting the image generator via the API on {params["address"]}...')
|
||||
response = requests.post(url=f'{params["address"]}/sdapi/v1/txt2img', json=payload)
|
||||
response.raise_for_status()
|
||||
r = response.json()
|
||||
|
||||
visible_result = ""
|
||||
for img_str in r['images']:
|
||||
image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
|
||||
if params['save_img']:
|
||||
output_file = Path(f'extensions/sd_api_pictures/outputs/{pic_id:06d}.png')
|
||||
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
|
||||
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
|
||||
output_file.parent.mkdir(parents=True, exist_ok=True)
|
||||
image.save(output_file.as_posix())
|
||||
pic_id += 1
|
||||
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||
image.thumbnail((300, 300))
|
||||
buffered = io.BytesIO()
|
||||
image.save(buffered, format="JPEG")
|
||||
buffered.seek(0)
|
||||
image_bytes = buffered.getvalue()
|
||||
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
||||
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
||||
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
|
||||
else:
|
||||
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
|
||||
image.thumbnail((300, 300))
|
||||
buffered = io.BytesIO()
|
||||
image.save(buffered, format="JPEG")
|
||||
buffered.seek(0)
|
||||
image_bytes = buffered.getvalue()
|
||||
img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
|
||||
visible_result = visible_result + f'<img src="{img_str}" alt="{description}">\n'
|
||||
|
||||
if params['manage_VRAM']:
|
||||
give_VRAM_priority('LLM')
|
||||
|
||||
return visible_result
|
||||
|
||||
# TODO: how do I make the UI history ignore the resulting pictures (I don't want HTML to appear in history)
|
||||
# and replace it with 'text' for the purposes of logging?
|
||||
|
||||
|
||||
def output_modifier(string):
|
||||
"""
|
||||
This function is applied to the model outputs.
|
||||
"""
|
||||
global pic_id, picture_response, streaming_state
|
||||
|
||||
global picture_response, params
|
||||
|
||||
if not picture_response:
|
||||
return string
|
||||
|
|
@ -125,17 +180,18 @@ def output_modifier(string):
|
|||
|
||||
if string == '':
|
||||
string = 'no viable description in reply, try regenerating'
|
||||
return string
|
||||
|
||||
# I can't for the love of all that's holy get the name from shared.gradio['name1'], so for now it will be like this
|
||||
text = f'*Description: "{string}"*'
|
||||
text = ""
|
||||
if (params['mode'] < 2):
|
||||
toggle_generation(False)
|
||||
text = f'*Sends a picture which portrays: “{string}”*'
|
||||
else:
|
||||
text = string
|
||||
|
||||
image = get_SD_pictures(string)
|
||||
string = get_SD_pictures(string) + "\n" + text
|
||||
|
||||
picture_response = False
|
||||
|
||||
shared.processing_message = "*Is typing...*"
|
||||
shared.args.no_stream = streaming_state
|
||||
return image + "\n" + text
|
||||
return string
|
||||
|
||||
|
||||
def bot_prefix_modifier(string):
|
||||
|
|
@ -148,42 +204,91 @@ def bot_prefix_modifier(string):
|
|||
return string
|
||||
|
||||
|
||||
def force_pic():
|
||||
global picture_response
|
||||
picture_response = True
|
||||
def toggle_generation(*args):
|
||||
global picture_response, shared, streaming_state
|
||||
|
||||
if not args:
|
||||
picture_response = not picture_response
|
||||
else:
|
||||
picture_response = args[0]
|
||||
|
||||
shared.args.no_stream = True if picture_response else streaming_state # Disable streaming cause otherwise the SD-generated picture would return as a dud
|
||||
shared.processing_message = "*Is sending a picture...*" if picture_response else "*Is typing...*"
|
||||
|
||||
|
||||
def filter_address(address):
|
||||
address = address.strip()
|
||||
# address = re.sub('http(s)?:\/\/|\/$','',address) # remove starting http:// OR https:// OR trailing slash
|
||||
address = re.sub('\/$', '', address) # remove trailing /s
|
||||
if not address.startswith('http'):
|
||||
address = 'http://' + address
|
||||
return address
|
||||
|
||||
|
||||
def SD_api_address_update(address):
|
||||
|
||||
global params
|
||||
|
||||
msg = "✔️ SD API is found on:"
|
||||
address = filter_address(address)
|
||||
params.update({"address": address})
|
||||
try:
|
||||
response = requests.get(url=f'{params["address"]}/sdapi/v1/sd-models')
|
||||
response.raise_for_status()
|
||||
# r = response.json()
|
||||
except:
|
||||
msg = "❌ No SD API endpoint on:"
|
||||
|
||||
return gr.Textbox.update(label=msg)
|
||||
|
||||
|
||||
def ui():
|
||||
|
||||
# Gradio elements
|
||||
with gr.Accordion("Stable Diffusion api integration", open=True):
|
||||
# gr.Markdown('### Stable Diffusion API Pictures') # Currently the name of extension is shown as the title
|
||||
with gr.Accordion("Parameters", open=True):
|
||||
with gr.Row():
|
||||
with gr.Column():
|
||||
enable = gr.Checkbox(value=params['enable_SD_api'], label='Activate SD Api integration')
|
||||
save_img = gr.Checkbox(value=params['save_img'], label='Keep original received images in the outputs subdir')
|
||||
with gr.Column():
|
||||
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Stable Diffusion host address')
|
||||
address = gr.Textbox(placeholder=params['address'], value=params['address'], label='Auto1111\'s WebUI address')
|
||||
mode = gr.Dropdown(["Manual", "Immersive/Interactive", "Picturebook/Adventure"], value="Manual", label="Mode of operation", type="index")
|
||||
with gr.Column(scale=1, min_width=300):
|
||||
manage_VRAM = gr.Checkbox(value=params['manage_VRAM'], label='Manage VRAM')
|
||||
save_img = gr.Checkbox(value=params['save_img'], label='Keep original images and use them in chat')
|
||||
|
||||
with gr.Row():
|
||||
force_btn = gr.Button("Force the next response to be a picture")
|
||||
generate_now_btn = gr.Button("Generate an image response to the input")
|
||||
force_pic = gr.Button("Force the picture response")
|
||||
suppr_pic = gr.Button("Suppress the picture response")
|
||||
|
||||
with gr.Accordion("Generation parameters", open=False):
|
||||
prompt_prefix = gr.Textbox(placeholder=params['prompt_prefix'], value=params['prompt_prefix'], label='Prompt Prefix (best used to describe the look of the character)')
|
||||
with gr.Row():
|
||||
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
||||
dimensions = gr.Slider(256, 702, value=params['side_length'], step=64, label='Image dimensions')
|
||||
# model = gr.Dropdown(value=SD_models[0], choices=SD_models, label='Model')
|
||||
with gr.Column():
|
||||
negative_prompt = gr.Textbox(placeholder=params['negative_prompt'], value=params['negative_prompt'], label='Negative Prompt')
|
||||
sampler_name = gr.Textbox(placeholder=params['sampler_name'], value=params['sampler_name'], label='Sampler')
|
||||
with gr.Column():
|
||||
width = gr.Slider(256, 768, value=params['width'], step=64, label='Width')
|
||||
height = gr.Slider(256, 768, value=params['height'], step=64, label='Height')
|
||||
with gr.Row():
|
||||
steps = gr.Number(label="Steps:", value=params['steps'])
|
||||
seed = gr.Number(label="Seed:", value=params['seed'])
|
||||
cfg_scale = gr.Number(label="CFG Scale:", value=params['cfg_scale'])
|
||||
|
||||
# Event functions to update the parameters in the backend
|
||||
enable.change(lambda x: params.update({"enable_SD_api": x}), enable, None)
|
||||
address.change(lambda x: params.update({"address": filter_address(x)}), address, None)
|
||||
mode.select(lambda x: params.update({"mode": x}), mode, None)
|
||||
mode.select(lambda x: toggle_generation(x > 1), inputs=mode, outputs=None)
|
||||
manage_VRAM.change(lambda x: params.update({"manage_VRAM": x}), manage_VRAM, None)
|
||||
manage_VRAM.change(lambda x: give_VRAM_priority('set' if x else 'reset'), inputs=manage_VRAM, outputs=None)
|
||||
save_img.change(lambda x: params.update({"save_img": x}), save_img, None)
|
||||
address.change(lambda x: params.update({"address": x}), address, None)
|
||||
|
||||
address.submit(fn=SD_api_address_update, inputs=address, outputs=address)
|
||||
prompt_prefix.change(lambda x: params.update({"prompt_prefix": x}), prompt_prefix, None)
|
||||
negative_prompt.change(lambda x: params.update({"negative_prompt": x}), negative_prompt, None)
|
||||
dimensions.change(lambda x: params.update({"side_length": x}), dimensions, None)
|
||||
# model.change(lambda x: params.update({"SD_model": x}), model, None)
|
||||
width.change(lambda x: params.update({"width": x}), width, None)
|
||||
height.change(lambda x: params.update({"height": x}), height, None)
|
||||
|
||||
force_btn.click(force_pic)
|
||||
generate_now_btn.click(force_pic)
|
||||
generate_now_btn.click(chat.cai_chatbot_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream)
|
||||
sampler_name.change(lambda x: params.update({"sampler_name": x}), sampler_name, None)
|
||||
steps.change(lambda x: params.update({"steps": x}), steps, None)
|
||||
seed.change(lambda x: params.update({"seed": x}), seed, None)
|
||||
cfg_scale.change(lambda x: params.update({"cfg_scale": x}), cfg_scale, None)
|
||||
|
||||
force_pic.click(lambda x: toggle_generation(True), inputs=force_pic, outputs=None)
|
||||
suppr_pic.click(lambda x: toggle_generation(False), inputs=suppr_pic, outputs=None)
|
||||
|
|
|
|||
|
|
@ -4,14 +4,7 @@ import torch
|
|||
from peft import PeftModel
|
||||
|
||||
import modules.shared as shared
|
||||
from modules.models import load_model
|
||||
from modules.text_generation import clear_torch_cache
|
||||
|
||||
|
||||
def reload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
shared.model, shared.tokenizer = load_model(shared.model_name)
|
||||
from modules.models import reload_model
|
||||
|
||||
|
||||
def add_lora_to_model(lora_name):
|
||||
|
|
|
|||
|
|
@ -1,3 +1,4 @@
|
|||
import gc
|
||||
import json
|
||||
import os
|
||||
import re
|
||||
|
|
@ -16,11 +17,10 @@ import modules.shared as shared
|
|||
|
||||
transformers.logging.set_verbosity_error()
|
||||
|
||||
local_rank = None
|
||||
|
||||
if shared.args.flexgen:
|
||||
from flexgen.flex_opt import CompressionConfig, ExecutionEnv, OptLM, Policy
|
||||
|
||||
local_rank = None
|
||||
if shared.args.deepspeed:
|
||||
import deepspeed
|
||||
from transformers.deepspeed import (HfDeepSpeedConfig,
|
||||
|
|
@ -182,6 +182,23 @@ def load_model(model_name):
|
|||
return model, tokenizer
|
||||
|
||||
|
||||
def clear_torch_cache():
|
||||
gc.collect()
|
||||
if not shared.args.cpu:
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def unload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
|
||||
|
||||
def reload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
shared.model, shared.tokenizer = load_model(shared.model_name)
|
||||
|
||||
|
||||
def load_soft_prompt(name):
|
||||
if name == 'None':
|
||||
shared.soft_prompt = False
|
||||
|
|
|
|||
|
|
@ -1,4 +1,3 @@
|
|||
import gc
|
||||
import re
|
||||
import time
|
||||
import traceback
|
||||
|
|
@ -12,7 +11,7 @@ from modules.callbacks import (Iteratorize, Stream,
|
|||
_SentinelTokenStoppingCriteria)
|
||||
from modules.extensions import apply_extensions
|
||||
from modules.html_generator import generate_4chan_html, generate_basic_html
|
||||
from modules.models import local_rank
|
||||
from modules.models import clear_torch_cache, local_rank
|
||||
|
||||
|
||||
def get_max_prompt_length(tokens):
|
||||
|
|
@ -101,12 +100,6 @@ def formatted_outputs(reply, model_name):
|
|||
return reply
|
||||
|
||||
|
||||
def clear_torch_cache():
|
||||
gc.collect()
|
||||
if not shared.args.cpu:
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
|
||||
def set_manual_seed(seed):
|
||||
if seed != -1:
|
||||
torch.manual_seed(seed)
|
||||
|
|
|
|||
10
server.py
10
server.py
|
|
@ -18,9 +18,8 @@ import modules.extensions as extensions_module
|
|||
from modules import api, chat, shared, training, ui
|
||||
from modules.html_generator import chat_html_wrapper
|
||||
from modules.LoRA import add_lora_to_model
|
||||
from modules.models import load_model, load_soft_prompt
|
||||
from modules.text_generation import (clear_torch_cache, generate_reply,
|
||||
stop_everything_event)
|
||||
from modules.models import load_model, load_soft_prompt, unload_model
|
||||
from modules.text_generation import generate_reply, stop_everything_event
|
||||
|
||||
# Loading custom settings
|
||||
settings_file = None
|
||||
|
|
@ -79,11 +78,6 @@ def get_available_loras():
|
|||
return ['None'] + sorted([item.name for item in list(Path(shared.args.lora_dir).glob('*')) if not item.name.endswith(('.txt', '-np', '.pt', '.json'))], key=str.lower)
|
||||
|
||||
|
||||
def unload_model():
|
||||
shared.model = shared.tokenizer = None
|
||||
clear_torch_cache()
|
||||
|
||||
|
||||
def load_model_wrapper(selected_model):
|
||||
if selected_model != shared.model_name:
|
||||
shared.model_name = selected_model
|
||||
|
|
|
|||
Loading…
Reference in a new issue